
The chasm between the scholarly record and grey literature

In January, nine organisations timed the release of new research with the specific aim of impacting the discussions of political and business leaders at the World Economic Forum in Davos. Three of the nine, sharing findings about global risks, tax, and trust, attracted significant media attention. None of the reports are available via a publisher. They matter not just because of their impact but because they are but the tip of a growing mountain of valuable research that is being posted, not published. And, because it is posted, not published, it’s a growing mountain of vital research that’s missing from the scholarly record.
How did we get here?
In 2012, as user-empowering Web 2.0 got into its stride, Clay Shirky, an NYU professor and internet ‘guru’, famously commented “Publishing is going away. Because . . . the incredible difficulty and complexity and expense of making something public. That’s not a job anymore. That’s a button. There’s a button that says “publish”, and when you press it, it’s done.”1 So, we got here partly because self-publishing became easy.
However, one consequence of replacing publishing with button-pressing was foreseen by writer and critic Robert Ebert in 1998. He wrote: “Doing research on the Web is like using a library assembled piecemeal by pack rats and vandalised nightly. To uncover the best thinking, you must shuffle through a universe populated by erroneous thinkers, non-thinkers, true believers, rabble-rousers, retailers, and teenagers with way too much time on their hands. Find what you’re looking for and bookmark it, and there’s a good chance that when you return you’ll discover the site has moved, (or) closed down.2”
That’s because Shirky forgot to mention that there’s also a button that says “delete”, and when you press it, it’s gone. Which is what happened when the publisher of Shirky’s interview, a blog called Findings, ran out of funding just weeks later. In fact, if you bookmarked either quote from Shirky or Ebert and tried to return today you’ll discover the dreaded “404 – page unknown”.
A recent report revealed that three-quarters of links fail within a decade. More worrying is that a similar percentage of links in scholarly content ‘drift’, in that they point to content that has changed since it was originally cited. It is hard to stand on the shoulders of giants if they disappear or shape-shift.
Of course, Shirky wasn’t entirely on the button because publishing hasn’t gone away. Millions of authors choose to have their research outputs transformed through complex and expensive processes to appear in online journals and e-book collections. As with their analogue forebears, once published, there is no delete button to ‘unpublish’ them. Quite the reverse, librarians and publishers work hard to ensure persistence and permanence: bookmark a persistent identifier and you can be confident it’ll resolve to a well-managed, stable, original publication, even if the publisher has gone out of business.
Even research content that isn’t captured in books and journals, such as data, code and other non-traditional outputs, is increasingly posted to repositories that adhere to the norms of the scholarly record.
Award-winning author Neil Gaiman called Ebert’s universe a “jungle”. When interviewed ahead of his 2010 McFadden Memorial lecture, he went on to say, “Google can bring you back 100,000 answers. A librarian can bring you back the right one.3” Librarians are wonderful, but wouldn’t it be equally wonderful if you could bring back the right one from the jungle yourself?
Plainly, for librarians and serious readers alike, simply pressing a button doesn’t make publishing ‘done’. Worse, it means there are two sources of knowledge: the well-organised scholarly record and a jungle of grey literature, with a bridge-less chasm between the two.
So, what makes publishing persistent and posting precarious?
The scholarly record is a place where reliable and reputable thinking has been checked, curated, prepared for discovery and then stored for the long run so that students and researchers – and, increasingly, thanks to open access, a broader public – can reliably ‘bring back’ what they need.
Publishers, librarians and, increasingly, the academic research community itself, collaborate in developing these standards, processes and infrastructure to capture content reliably and securely for the scholarly record.
Shirky was right to think that publishing is incredibly difficult, complex and expensive, but even he probably didn’t imagine how much more so now that digital has unlocked so many new possibilities, like PIDs and full-text (including supplementary text and data) in machine-readable formats.
You only have to look at the requirements set out by cOAlition S, or INASP’s Journal Publishing Practices and Standards (JPPS) to realise how many complex requirements there are for metadata, persistent identifiers, and preservation for journal articles. The FAIR Principles and initiatives like Force 11 seek to ensure data and other non-traditional outputs are just as findable, accessible, interoperable and reusable. Increasingly, the scholarly record now depends on persistent identifiers: ORCIDs for people; INSI, Ringgold, GRID and ROR for institutions; RAiDs for projects; DOIs for research outputs and for grants; and FunderID for funders.
Building a scholarly record where content is reliably findable, accessible, interoperable, and reusable – even by machines – isn’t cheap. It requires skills, time and effort – and sometimes the need to pay for services (persistent identifier systems like ORCIDs and DOIs don’t come for free). Even when captured to the right standards, the content then needs to be channelled into library systems, specialist discovery services and dark archives, which means building and maintaining a network of professional and technical relationships with third-party partners and their platforms.
One clue to the scale of the “incredible difficulty and complexity and expense of making something public” for the scholarly record is in the fees charged by open access publishers. The cost per article in a mainstream journal is in the range $2,700–4,700. Publishing an open access book will set you back anything from $3,000 to $13,000. According to Delta Think, the market for OA journal articles will be around $2.4BN next year, 50% up from $1.6BN in 2021. But it’s worth it. A recent report confirms that comprehensive adoption of PIDs brings millions of dollars of efficiency gains.
Yet Shirky’s prediction was also on the mark. Thousands of research organisations, like the ‘Davos nine’, eschew publishers. Some, like the IPCC, have switched away from them. This is not to say that they should work with publishers, but they could follow the lead of organisations like OECD or World Bank and self-publish using scholarly norms. But few do.
Let’s explore why. Self-publishing is above all about taking control. Control over timing is vital where organisations, like the Davos nine, seek to influence events. Control over presentation is important for branding-building, vital when it comes to scrapping for funding. Self-publishing also brings the organisation into direct contact with audiences and generates usage and download data: important when reporting to existing funders and securing new ones.
And, of course, button-pressing is cheaper than outsourcing to a full-service publisher.
However, button-pressing organisations fall into what I call the ‘Shirky Trap’ because, in eschewing scholarly publishing norms, their content becomes ‘grey literature’.
Grey literature is content that’s hard for librarians to collect and, because it sits outside the scholarly record, it’s hard for researchers and students to find. It’s content that’s shuffled among the musings of fact-deniers, snake-oil salesmen and celebrity gossipers in the rat-packers’ jungle, which leads many to think it hasn’t been through peer-review – when, in fact, most has4. However, the biggest problem is that grey literature is at risk of nocturnal vandals.
I recently spoke with an NGO that advocates reform in international trade. As part of their mission, they undertake and publish research, which they post in a ‘library’ on their website. Except, when I visited earlier this year, I found that every link in the library was broken. What was shocking was that their communications manager and webmaster hadn’t realised. The links had broken during a rebuild of their website six months prior and no-one had had time to check.
As the webmaster explained, they are a communications-led organisation. Their priorities are running campaigns, changing influential minds and fundraising, not publishing. So it’s no wonder that neither of them had heard about PIDs or other standards used by scholarly publishers.
Their latest research report, released in early January in support of a campaign, attracted a good degree of media and social media attention – which is how I heard about it. But by the end of the month, it had been displaced from their homepage by another campaign and can now only be found by delving into their library – if, that is, you can find the link because it is buried deep in their website. The links in their library are now fixed but their publications still languish outside the scholarly system because the architecture of their website means we can’t index them in Policy Commons, my new project.
This is not an isolated example. In building Policy Commons we have identified over 20,000 self-publishing organisations and keep finding more: not all research occurs in academia.
Communications-led organisations are often good at making research newsworthy, impactful and accessible to an audience outside the ivory towers of academia. They are skilled at engaging with audiences and building contacts with journalists and social media influencers. They’re just no good at getting their research into the scholarly record.
In a world where recouping publishing costs from sales has all but disappeared and funding for publishing is getting harder to find, button pressing is bound to be an attractive option for research organisations whose authors’ careers are not dependent on being published in the ‘right’ journal. Cash-strapped, mission-driven organisations where the management focus is on winning headlines, influence and impact will invest in communicators and communications, not publishers and publishing.
Two sides of the ‘reader’ coin
Having worked for both scholarly publishers and self-publishing research organisations, I’ve learned that there are two sides to making research public. On one side is everything that publishers do well, but communications-led organisations don’t. On the other side is everything communications-led organisations do well, but publishers don’t.
I believe each can learn lessons from the other and readers, both scholarly and not, would be better off if they did – not least because it could help with fundraising and satisfy funders looking for broader societal returns on their investments.
The acid test is this: how reader-ready is your content? Reader-readiness can be split into six segments:
- Discoverability: publishers and organisations will know all about SEO for public search engines like Google, but what steps are taken to make sure content is discoverable in the specialist indexes and abstracting services, like Google Scholar? Ignore them and you’ll miss out on >70% of scholars’ searches. Publishers are good at both. Self-publishing organisations miss out on the latter.
- Readers’ networks: Word-of-mouth and recommendations are powerful tools to win new readers. Are links to your content appearing in your readers’ email and online feeds? Is your content easily citable in articles, posts and bibliographies? Publishers are highly skilled in making content citable and links are persistent. Most self-publishing organisations know nothing about DOIs, so link rot is rife.
- Utility and reader workflows: Again, publishers score highly here because they capture content in industry-standard ways to suit workflow tools (which they often own!), self-publishing organisations lack this knowledge. Worse, being communications-led, style and visual impact is prioritised ahead of utility.
- Access and accessibility: Here, organisations do better. Keen to reach non-specialist audiences, they invest in writers, press releases, executive summaries, policy briefs, infographics and translations. Publishers do well with summaries (abstracts and blurbs) but non-specialist audiences will struggle with ‘jargon-monoxide’ and academia’s dry, rigid, formats.
- Protection from vandals: Publishers get top marks here, in addition to using persistent identifiers they ensure their content is preserved in legal-deposit libraries and dark archives, ready to be unlocked if they go out of business. Many organisations get negative marks because they actively delete old content believing it to be out of date or when in conflict with their latest messages. Few provide copies to national libraries or make provision for ongoing access in case of their demise.
- Launch and post-launch awareness: Organisations do far better here. As the example of the ‘Davos nine’ shows, launches are often timed to coincide with events to win maximum attention. Regular contact with journalists, bloggers and influencers results in significant mainstream and social media coverage. However, both publishers and organisations tend to ‘launch and leave’, spending little on promoting their content post-launch or thinking to re-release it should an opportunity arise.
Figure 1 summarises how publishers and self-publishing organisations make their content reader-ready: each has work to do.
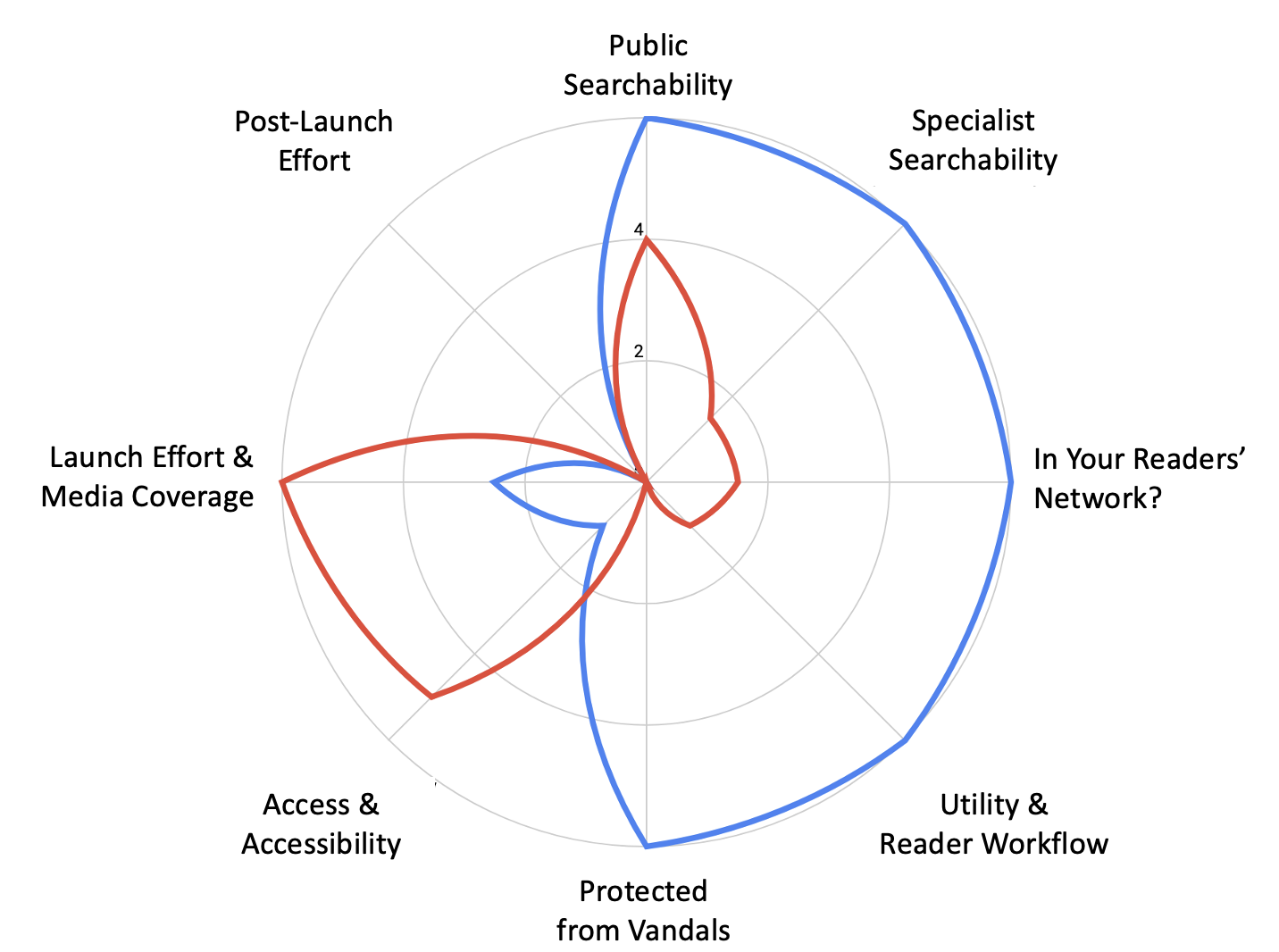
Figure 1: Reader-readiness for a typical publisher publication (blue) and a typical self-publishing organisation publication (red).
For publishers and their authors, services like Kudos, Scholarcy, and SciencePOD are popping up to help develop the ‘red’ side of reader-readiness. But what about help for self-publishing organisations to develop their ‘blue’ side, to be able to reach across the chasm to the scholars?
In view of their number, the mountain of reports involved (an estimated 400,000 new reports per year) and their lack of funds, I think it must be done on their behalf. And that’s why we’ve developed Policy Commons: to be a bridge between the jungle and the scholarly record.
With Policy Commons, we have built tools that reach into the jungle to find and index research-quality content from trustworthy, self-publishing, organisations. Once captured, we ‘tame’ each item, creating for each a standard metadata record, complete with a persistent identifier. In some cases we have to create a summary. To protect from link rot, we take a copy of the full text item and store it in a dark archive. Since Policy Commons’ launch in 2021, we have indexed and generated persistent landing pages for over 3.5 million reports, and our users benefit from a full-text search engine. We even pull tables out of the PDFs so users can export the data as a csv file.
Our next step is to ‘inject’ this content into the scholarly record. We have already partnered with Google Scholar and are in discussions with other specialised discovery services. For librarians, we have just developed a MARC-record feed, using KBART, for titles that have complete metadata.
Taming isn’t easy and I won’t claim that every item is as polished as a journal article or book. That’s because we’re working with publications that have been produced in non-standard ways and are then posted on button-powered websites of widely varying design and quality. The result is a fair amount of ‘noise’ in the metadata records, but we continue our noise-reduction efforts by refining and improving our taming tools.
In January, the Davos nine were all tamed in Policy Commons and have now taken their place in the scholarly record, as were another 34,344 reports from 29 other organisations. A few, like the fair trade report, were indexed by hand because they were too wild for our automated tools.
Over time and with improved tools fewer reports will be left languishing in the jungle shuffled among the thoughts of erroneous thinkers, non-thinkers, true believers, rabble-rousers, retailers and teenagers. With Policy Commons as a bridge, researchers and librarians will be able to ‘bring back’ grey literature as easily and reliably as if they had been released into the scholarly record by a publisher.
Toby Green is a co-founder of Coherent Digital
References:
1. https://policycommons.net/artifacts/2676517/how-we-will-read_-clay-shirky/3699667/
2. https://web.archive.org/web/19991007161135/http://www1.zdnet.com/yil/content/columnists/ebert9809.html
3. https://www.youtube.com/watch?v=uH-sR1uCQ6g
4. https://policycommons.net/artifacts/2393588/untitled/3415116/